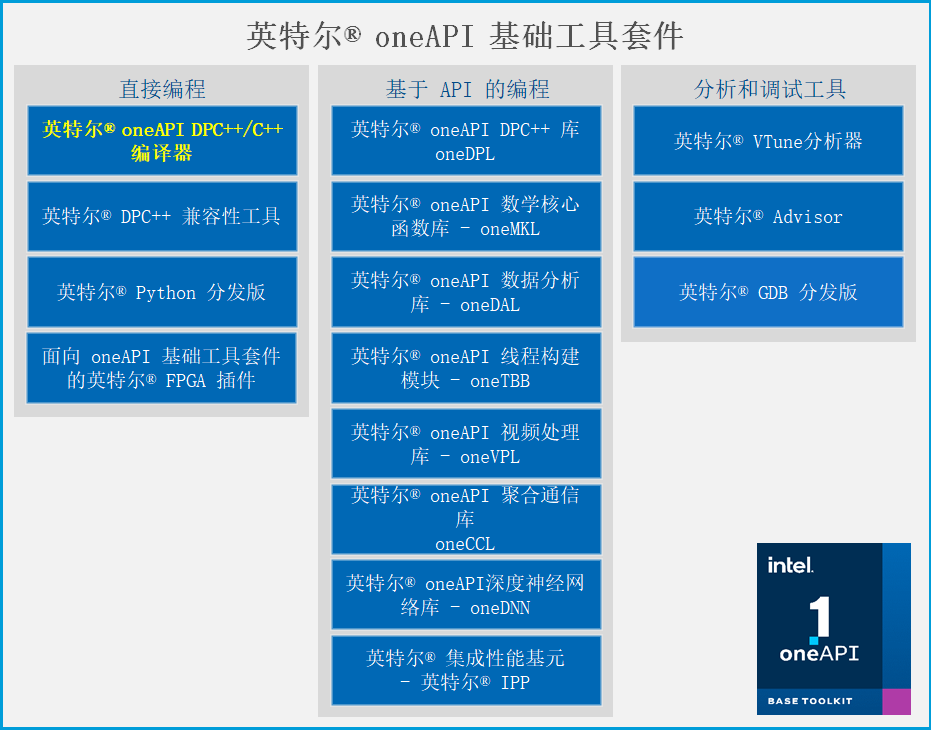
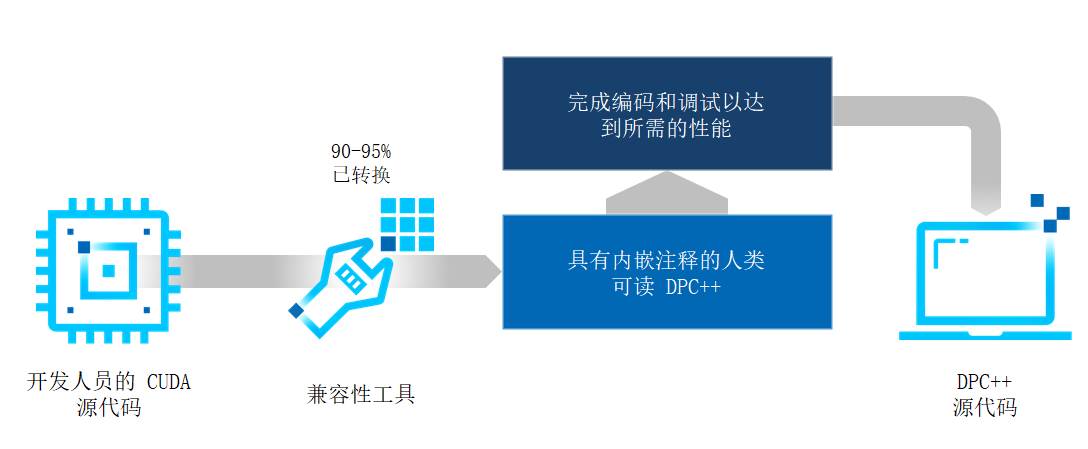
Ⅰ DPC++简介DPC++是Data Parallel C++(数据并行C++)的首字母缩写,它是Intel为了将SYCL引入LLVM和oneAPI所开发的开源项目。SYCL是为了提高各种加速设备上的编程效率而开发的一种高级别的编程模型,简单来说它是一种跨平台的抽象层,用户不需要关心底层的加速器具体是什么,按照标准编写统一的代码就可以在各种平台上运行。可以说SYCL大大提高了编写异构计算代码的可移植性和编程效率,已经成为了异构计算的行业标准。值得一提的是SYCL并不是由多个单词的首字母的缩写。DPC++正是建立在SYCL和现代C++语言之上,具体来说是建立在C++17标准之上的。
Ⅱ DPC++背景 1.什么是数据并行编程 数据并行编程既可以被描述为一种思维方式,也可以被描述为一种编程方式。 数据由一组并行的处理单元进行操作。 每个处理单元都是能够对数据进行计算的硬件设备。这些处理单元可能存在于单个设备上,也可能存在于我们计算机系统中的多个设备上。 我们可以指定代码以内核的形式处理我们的数据。
2.什么是异构系统 异构系统是包含多种类型的计算设备的任何系统。 例如,同时具有CPU和GPU的系统就是异构系统。现在已经有很多中这样的计算设备了,包括 CPU、GPU、FPGA、DSP、ASIC和AI 芯片。异构系统的出现带来了一个很大的挑战,就是刚刚提到的这些设备,每一种都具有不同的架构,也具有不同的特性,这就导致对每个设备有不同编程和优化需求,而DPC++开发一个动机就是帮助解决这样的挑战。
3.为什么需要异构系统 因为异构计算很重要,一直以来计算机架构师致力于限制功耗、减少延迟和提高吞吐量的工作。从1990年到2006年,由于处理器性能每两到三年翻一番(主要是因为时钟频率每两年翻一番),导致那个时候应用程序的性能都跟着有所提升。这种情况在2006年左右结束,一个多核和多核处理器的新时代出现了。由于架构向并行处理的转变为多任务系统带来了性能提升,但是在不改变编程代码的情况下,并没有为大多数现有的单个应用程序带来性能提升。在这个新时代,GPU等加速器因为能够更高效的加速应用程序变得比以往任何时候都流行。这催生了一个异构计算时代,诞生了大量的具有自己的专业处理能力的加速器以及许多不同的编程模型。它们通过更加专业化的加速器设计可以在特定问题上提供更高性能的计算,因为它们不必去处理所有问题。这是一个经典的计算机架构权衡。它通常意味着加速器只能支持为处理器设计的编程语言的子集。事实上,在DPC++中,只有在内核中编写的代码才能在加速器中运行。
4.为什么使用DPC++ 一方面因为DPC++具有可移植性、高级性和非专有性,同时满足现代异构计算机体系结构的要求。另一方面,它可以让跨主机和计算设备的代码使用相同的编程环境,即现代C++的编程环境。最后,计算机体系结构的未来包括跨越标量、向量、矩阵和空间 (SVMS) 操作的加速器,需要对包括 SVMS 功能在内的异构机器的支持。并且这种支持应该涵盖高度复杂的可编程设备,以及可编程性较低的固定功能或专用的设备。
Ⅲ 初探DPC++ 在开始讨论现代C++语言在DPC++中的应用之前,让我们先看一遍完整的代码,顺便测试我们的实验环境:
#include <CL/sycl.hpp> constexpr int N = 16 ;using namespace sycl;class IntelGPUSelector : public device_selector { public : int operator () (const device& Device) const override const std::string DeviceName = Device.get_info <info::device::name>(); const std::string DeviceVendor = Device.get_info <info::device::vendor>(); return Device.is_gpu () && (DeviceName.find ("Intel" ) != std::string::npos) ? 100 : 0 ; } }; int main () IntelGPUSelector d; queue q (d) ; int * data = malloc_shared <int >(N, q); q.parallel_for (N, [=](auto i) { data[i] = i; }).wait (); for (int i = 0 ; i < N; i++) std::cout << data[i] << " " ; free (data, q); }
编译运行上面的代码,如果没有问题应该输出:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
简单解释一下这段代码,sycl是DPC++的实体的命名空间,用using namespace sycl;打开命名空间可以简化后续代码。IntelGPUSelector是一个继承了device_selector的设备选择器,其中device_selector是纯虚类,它有个纯虚函数int operator()(const device& Device) const需要派生类来实现,该函数会遍历计算机上的计算设备,并且返回使用设备的优先级,返回数字越高优先级越高,这里选择Intel的GPU作为首选的计算设备,注意这个函数使用了override来说明其目的是覆盖虚函数。queue的目的是指定工作的目标位置,这里设置的是Intel的GPU。函数模板malloc_shared分配了可在设备上使用的工作内存。成员函数parallel_for执行并行计算。值得注意的是free调用的是sycl::free而不是C运行时库的free。在这段代码中,比较明显使用了现在C++语法的地方是函数parallel_for的实参,
[=](auto i) { data[i] = i; }
这是一个lambda表达式。[=]是捕获列表,它可以捕获当前定义作用域内的变量的值,这也是它可以在函数体内使用data[i]的原因。捕获列表[=]之后的是形参列表(auto i),注意这里的形参类型使用的是auto占位符,也就是说,我们将形参类型的确认工作交给了编译器。我们一般称这种lambda表达式为泛型lambda表达式。当然,如果在编译时选择C++20标准,我们还可以将其改为模板语法的泛型lambda表达式:
[=]<typename T>(T i) { data[i] = i; }
lambda表达式的捕获列表功能非常强大,除了捕获值以外,还可以捕获引用,例如:
[&](auto i) { data[i] = i; }
以上代码会捕获当前定义作用域内的变量的引用,不过值得注意的是,由于这里的代码会交给加速核心运行,捕获引用并不是一个正确的做法,会导致编译出错。另外一般来说,我们并不推荐直接捕获所有可捕获的对象,而是有选择的捕获,例如:
[data](auto i) { data[i] = i; }
当然,除了使用lambda表达式,我们也可以选择其他形式的代码来运行设备,比如使用仿函数:
struct AssginTest { void operator () (auto i) const int * data_; }; AssginTest functor{data}; q.parallel_for (N, functor).wait ();
但是很明显,这种方法没有使用lambda表达式来的简单直接。
Ⅴ DPC++和泛型能力 之所以能够让parallel_for这么灵活的接受各种形式的实参,是因为parallel_for本身是一个成员函数模板:
template <typename KernelName = detail::auto_name, typename KernelType>event parallel_for (range<1 > NumWorkItems, _KERNELFUNCPARAM(KernelFunc) _CODELOCPARAM(&CodeLoc)) { _CODELOCARG(&CodeLoc); return parallel_for_impl <KernelName>(NumWorkItems, KernelFunc, CodeLoc); }
其中KernelFunc就是传入的lambda表达式或者仿函数,KernelType是KernelFunc的类型。submit_impl:
sycld.dll!cl::sycl::queue::submit_impl dpcpp.exe!cl::sycl::queue::submit dpcpp.exe!cl::sycl::queue::parallel_for_impl dpcpp.exe!cl::sycl::queue::parallel_for
这是因为sycld.dll是一个二进制模块,它无法以模板的形式提供代码,所有的类型必须确定下来,为了解决这个问题,cl::sycl::queue::submit_impl使用了std::function:
event submit_impl (function_class<void (handler &)> CGH, const detail::code_location &CodeLoc)
函数模板cl::sycl::queue::parallel_for_impl将KernelFunc封装到另外一个lambda表达式对象中,并且通过function_class<void(handler &)>来传递整个lambda表达式:
template <typename KernelName = detail::auto_name, typename KernelType, int Dims> event parallel_for_impl ( range<Dims> NumWorkItems, KernelType KernelFunc, const detail::code_location &CodeLoc = detail::code_location::current ()) { return submit ( [&](handler &CGH) { CGH.template parallel_for <KernelName, KernelType>(NumWorkItems, KernelFunc); }, CodeLoc); }
其中function_class就是std::function。注意这里CGH.template parallel_for需要说明符template否则尖括号会解析出错。DPC++通过这样一系列的操作,最大限度的保留了用户编程的灵活性。
Ⅵ DPC++和模板推导 DPC++代码中大量的运用了C++17标准才引入的模板推导特性,关于这些特性我们还是从一个DPC++的小例子开始:
int main () IntelGPUSelector d; queue q (d) ; std::vector<int > v1 (N) ; std::array<int , N> v2; { buffer buf1 (v1) ; buffer buf2 (v2) ; q.submit ([&](handler& h) { accessor a1 (buf1, h, write_only); accessor a2 (buf2, h, write_only); h.parallel_for (N, [=](auto i) { a1[i] = i; a2[i] = i; }); }); } for (int i = 0 ; i < N; i++) std::cout << v1[i] << v2[i] << " " ; }
这段代码没有使用malloc_shared分配内存,取而代之的是使用buffer和accessor,其中buffer用于封装数据,accessor用于访问数据。这里以buffer为例解析DPC++对模板推导的使用。std::vector<int>和std::array<int, N>类型。之所以能够这样调用构造函数,并不是因为buffer为这两个类型重载了它的构造函数,而是因为其构造函数使用了模板。这里涉及到一个C++17标准新特性——类模板的模板实参推导。在以往,类模板的实例化必须是显式传入模板实参,否则会造成编译出错。在新的标准中,类模板的模板实参已经可以根据构造函数来推导了。来看一下buffer的构造函数:
template <typename T, int dimensions = 1 , typename AllocatorT = cl::sycl::buffer_allocator, typename = typename detail::enable_if_t <(dimensions > 0 ) && (dimensions <= 3 )>> class buffer {public :... template <class Container, int N = dimensions, typename = EnableIfOneDimension<N>, typename = EnableIfContiguous<Container>> buffer (Container &container, AllocatorT allocator, const property_list &propList = {}) : Range (range <1 >(container.size ())) { impl = std::make_shared <detail::buffer_impl>( container.data (), get_count () * sizeof (T), detail::getNextPowerOfTwo (sizeof (T)), propList, make_unique_ptr<detail::SYCLMemObjAllocatorHolder<AllocatorT>>( allocator)); } template <class Container , int N = dimensions, typename = EnableIfOneDimension<N>, typename = EnableIfContiguous<Container>> buffer (Container &container, const property_list &propList = {}) : buffer (container, {}, propList) {} ... };
代码buffer buf1(v1);会执行
buffer (Container &container, const property_list &propList = {})
这条构造函数,值得注意的是该构造函数并没有实际的实现代码,而是通过委托构造函数的方法调用了
buffer (Container &container, AllocatorT allocator, const property_list &propList = {})
委托构造函数是C++11引入的特性,它可以让某个构造函数将构造的执行权交给另外的构造函数。回到模板推导,这里通过构造函数会推导出Container是std::vector<int>,dimensions的推导结果是1,而后面两个模板参数是用来检查前两个模板参数是否正确的,这里大量的使用了模板元编程的技巧:
template <int dims>using EnableIfOneDimension = typename detail::enable_if_t <1 == dims>;template <class Container >using EnableIfContiguous = detail::void_t <detail::enable_if_t <std::is_convertible< detail::remove_pointer_t <decltype ( std::declval <Container>().data ())> (*)[], const T (*)[]>::value>, decltype (std::declval <Container>().size ())>;
首先它们都是使用using定义的别名模板,它们的目的分别是检查dims是否为1和Container是否为连续的。第一个别名模板很简单,直接检查dims是否为1,detail::enable_if_t就是std::enable_if_t。第二个检查连续性的方法稍微麻烦一些,简单来说就是检查容器对象的成员函数data()返回值的类型的数组指针是否能和const T (*)[]转换,这里主要检查两点,第一容器具有data()成员函数,第二返回类型的指针和T const T (*)[]转换。事实上,在标准容器中,只有连续容器有data()成员函数,其他的都会因为没有data()而报错,例如:
no member named 'data' in 'std::list<int>'
仔细阅读上面代码的朋友应该会发现另外一个问题,那就是没有任何地方可以帮助编译器推导出buffer的类模板形参T。这就不得不说DPC++将C++17关于模板推导的新特性用的淋漓尽致了。实际上在代码中,有这样一句用户自定义推导指引的代码:
template <class Container >buffer (Container &, const property_list & = {}) ->buffer<typename Container::value_type, 1 >;
用户自定义推导指引是指程序员可以指导编译器如何通过函数实参推导模板形参的类型。最后在这个例子中,需要注意一下,buffer在析构的时候才会将缓存的数据写到v1和v2,所以这里用了单独的作用域。
~buffer_impl () { try { BaseT::updateHostMemory (); } catch (...) { } }
Ⅶ 总结 本篇文章从几个简单的DPC++的例子展开,逐步探究了DPC++对于现代C++语言特性的运用,其中比较重要的包括lambda表达式、泛型和模板推导,当然DPC++运用的新特性远不止这些。从另一方面来看,这些新特性的加入确实的帮助DPC++完成了过去无法完成的工作,这也是近几年C++的发展趋势,越来越多的代码库开始引入新的特性,并且有一些非常”神奇“的代码也孕育而生。DPC++就是其中之一,光是阅读DPC++中使用新特性的代码就已经足够让人拍案叫绝了,更何况还有代码的组织架构、底层的抽象等等。我知道,单单一篇文章并不能讨论清楚DPC++中现代C++语言的特性,所以王婆卖瓜的推荐自己写的书《现代C++语言核心特性解析 》和盛格塾课程《现代C++42讲》,相信看完这本书或者经过课程训练后朋友们会对现代C++语言的特性有一个比较深入的理解。
参考文献 1.DPC++ Part 1: An Introduction to the New Programming Model [https://simplecore-ger.intel.com/techdecoded/wp-content/uploads/sites/11/Webinar-Slides-DPC-Part-1-An-Introduction-to-the-New-Programming-Model-.pdf] https://resource-cms.springernature.com/springer-cms/rest/v1/content/17382710/data/v1] https://software.intel.com/en-us/devcloud/oneapi] https://insidehpc.com/2020/06/new-open-dpc-extensions-complement-sycl-and-c/]