这是一篇描述DPC++编译器架构和原理的翻译,原文为:https://intel.github.io/llvm-docs/design/CompilerAndRuntimeDesign.html,读完这篇文章能够大概理解DPC++编译器是如何将不同架构的代码编译在一起并一起运行起来的。
整篇翻译长达2万多字,也算是对读者和自己的年终钜献了吧。
博客又坚持了一年,真不容易。
这是一篇描述DPC++编译器架构和原理的翻译,原文为:https://intel.github.io/llvm-docs/design/CompilerAndRuntimeDesign.html,读完这篇文章能够大概理解DPC++编译器是如何将不同架构的代码编译在一起并一起运行起来的。
整篇翻译长达2万多字,也算是对读者和自己的年终钜献了吧。
博客又坚持了一年,真不容易。
在9月份的博客文章中我提到要把C++大会分享的主题写成总结文字发出来。拖拖拉拉的磨蹭了快两个月,终于能把这篇文章发出来了。
周末时候和朋友聊了一下C++的智能指针,突然发现虽然智能指针进入C++11标准库已经有十多年了,但是我们对部分细节的理解还是比较局限,以std::weak_ptr为例,很多人的理解只是停留在避免std::shared_ptr出现相互引用,导致对象无法析构,内存无法释放的问题。
当然,并不是说这种用法有什么不对,恰恰相反,它是一个非常经典的使用场景。但是std::weak_ptr的使用场景或者说它诞生的理念却不仅仅是这些,如果没有更加透彻理解std::weak_ptr,也很难合理的使用std::shared_ptr。
std::weak_ptr从概念上,它是一个智能指针,相对于std::shared_ptr,它对于引用的对象是“弱引用”的关系。简单来说,它并不“拥有”对象本身。
如果我们去类比生活中的场景,那么它可以是一个房地产中介。房地产中介并不拥有房子,但是我们有办法找到注册过的房产资源。在客户想要买房子的时候,它起初并不知道房子是否已经卖出了,它需要找到房主询问后再答复客户。std::weak_ptr做的事情几乎和房产中介是一模一样的。std::weak_ptr并不拥有对象,在另外一个std::shared_ptr想要拥有对象的时候,它并不能做决定,需要转化到一个std::shared_ptr后才能使用对象。所以std::weak_ptr只是一个“引路人”而已。
说了这么多,那么std::weak_ptr除了解决相互引用的问题,还能做什么?答案是:一切应该不具有对象所有权,又想安全访问对象的情况。
还是以互相引用的情况为例,通常的场景是:一个公司类可以拥有员工,那么这些员工就使用std::shared_ptr维护。另外有时候我们希望员工也能找到他的公司,所以也是用std::shared_ptr维护,这个时候问题就出来了。但是实际情况是,员工并不拥有公司,所以应该用std::weak_ptr来维护对公司的指针。
再举一个例子:我们要使用异步方式执行一系列的Task,并且Task执行完毕后获取最后的结果。所以发起Task的一方和异步执行Task的一方都需要拥有Task。但是有时候,我们还想去了解一个Task的执行状态,比如每10秒看看进度如何,这种时候也许我们会将Task放到一个链表中做监控。这里需要注意的是,这个监控链表并不应该拥有Task本身,放到链表中的Task的生命周期不应该被一个观察者修改。所以这个时候就需要用到std::weak_ptr来安全的访问Task对象了。
最后再来聊一个新手使用std::weak_ptr容易被坑的地方:对象资源竞争。以下代码在多线程程序中是存在很大风险的,因为wp.expired()和wp.lock()运行的期间对象可能被释放:
// std::weak_ptr<SomeClass> wp{ sp }; |
正确的做法是:
auto sp = wp.lock(); |
std::weak_ptr的lock函数是一个原子操作。有趣的是,最开始的C++11标准是没有提到原子操作的,C++14标准才对这一点进行了补充,详细过程可以参考提案文档:LWG2316。
作为一个搞C++技术的人,9月的最后几天时间是值得开心的。因为由于疫情原因取消了一年的全球C++及系统软件技术大会,终于在9月28、29两天顺利开幕。虽然我的时间很紧张,28号下午才到,错过了开幕,29号急匆匆的昨晚演讲就离开上海,但是期间也和很多老朋友见面聊天。
这次C++大会因为有Intel oneAPI对我的赞助,演讲主体选择了异构计算相关的内容,主要是讲述通过sycl进行异构计算的方法,并且描述了dpc++编译器编译单一源代码的过程。对此有兴趣的朋友可以看看我分享的ppt,后续有机会可能会把分析内容总结为文章发表出来。
这年头,参加一次线下技术大会实属不易,当然举办方就更加不容易了。这届K+大会举办地是深圳,好巧不巧,开幕前一周深圳出现疫情,大会临时将举办地点从迁移到没有疫情的区域,只用了一周时间,可想而知这个事情有多难。
到举办酒店后,确实能感受到举办方满满的诚意和热情,这让我是没想到的,尤其是举办方为了每个讲师准备了精美的伴手礼,我第一时间也发了朋友圈,表示了感谢。到酒店之后就没什么好说的了,这次演讲是第一天,这很好因为可以赶回家和家人度过周日。
回家的过程也很顺利,并没有弹窗,这也要归功于举办方提供的出行建议,周六的23点顺利到家,没有任何阻碍。
这次在大会上讲的主体是《C++新标准细节简析》,讲这个也没有什么特别的理由,就是觉得去讲一些大家都知道的东西,或者标准中一些重要的东西没什么意思,因为重要的大家都有所了解,所以想讲点细节,可能知道的人并不多。
最后再说一下K+大会的特点,大会主要还是以技术上层的东西居多,技术底层和技术细节相对较少,比如第一届的主体是云原生,第二届的主体是能效,而底层技术主要是张银奎老师出品的论坛,我有幸也是这个论坛的讲师之一。如果要提一个希望,那就是希望K+大会更加重视基础和底层,邀请更多做底层技术的专家参加到论坛。大厦不可能没有地基,所有看起来华丽的架构都需要底层的支持,反过来说有了底层的支持,华丽的上层技术才不会沦为虚无缥缈的表面繁荣。
我还是非常支持K+大会的,有这样的大会举办方我相信K+大会会成为国内最顶尖的技术会议之一。
最后,奉上K+大会的PPT:
在我们学习C++编程的时候,通常都会被告诫:“不要在构造函数中调用虚函数”。为什么会有这样一条规则呢?从语法上来看,当构造函数的函数体执行的时候,该类的虚表和虚表指针应该已经准备就绪了,不会造成调用失败或者引发未定义行为,例如:
|
当然,它的派生类不会在此时构造好虚表指针,不可能调用到派生类的虚函数,所以上述代码会有如下的执行结果:
A() |
这个结果显然是合理的,因为基类B在构造的时候,C还没有构造,这个时候调用B类的虚函数是安全的。那么回到开始的问题,为什么建议大家不要在构造函数中调用虚函数呢?我认为最重要的原因是他的行为跟通常使用虚函数的时候有一些差异,容易造成理解偏差。比如上面的代码,一般情况下,如果在C类构造完毕后调用foo函数,那么调用的必然是C::foo()这个函数。
另外,C++构造函数中调用虚函数和其他语言的行为也会有所不同,这也会造成程序员某种程度上的记忆偏差,最终导致程序设计出现问题。下面,我们以C#和Java为例来展示这种偏差:
using System; |
编译运行这份C#代码,输出结果为:
From derived |
再来看看Java的情况:
class Program { |
编译运行这份代码,输出结果的和C#相同:
From derived |
由此可见,这些不同的结果确实容易影响到程序员的记忆。
最后值得一提的是,C++的这种处理从安全性上更好,这一点非常明显,无论是C#还是Java,在基类中调用派生类虚函数或者说调用被派生类重写的方法,执行的代码都会在派生类构造之前执行,造成未定义的行为。
在我写的《现代C++语言核心特性解析》中有一个小节是讲解的返回值优化,在这篇文章中,我将对这部分内容进行一点补充,将更多细节展示出来。
首先还是来看看书中的这段代码:
|
这段代码在开启和关闭拷贝消除的运行情况是不同的,不过书中只使用了两种情况讨论,但是实际上我漏掉了C++17关闭拷贝消除的情况,以下是正确的对比表格:
| 拷贝消除 | C++14 关闭拷贝消除 | C++17 关闭拷贝消除 |
|---|---|---|
| X ctor | X ctor | X ctor |
| X dtor | X copy ctor | X copy ctor |
| X dtor | X dtor | |
| X copy ctor | X dtor | |
| X dtor | ||
| X dtor |
可以看到C++17和C++14的行为是不同的。开启拷贝消除的很明显,优化让构造直接发生在main函数中:
make_x(): # @make_x() |
C++14的行为也很明确,和书中介绍了一样,发生了三次构造:
make_x(): # @make_x() |
但是C++17的行为相对就比较奇怪了,关闭拷贝消除但并没有完全关闭:
make_x(): # @make_x() |
只有两次构造,x1拷贝到临时对象,临时对象拷贝到x2的过程合并成了一次,也就是x1直接拷贝到了x2,这是为什么呢?
其实是因为C++17对临时对象进行了特殊规定:
6.7.7 Temporary objects [class.temporary]
The materialization of a temporary object is generally delayed as long as possible in order to avoid creating unnecessary temporary objects.
在提案文档p0135r1中也对拷贝消除的描述进行了修改(http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0135r1.html
)。
至此,我们已经了解了C++17关闭拷贝消除后的特殊情况的因由。最后补充一点,关于拷贝消除,除了在返回值上可以做优化,还有下面这些情况都可以进行优化,当然有一些优化是没有实现的:
- return语句中返回类类型,返回对象类型和函数返回类型相同,并且要求类型是非易失且有自动存储周期的对象。
- throw表达式,操作数类型也要求是非易失且有自动存储周期的对象,并且作用域不超过最内侧的try。
- 异常处理(其实就是try-catch中catch(){}),声明的对象如果和抛出对象类型相同,可以将声明对象看作抛出对象的别名,前提条件是这个对象在这个过程中除了构造和析构是不会被改变的。
- 在协程中,协程参数的拷贝可以被忽略,也就是直接引用参数本身,当然也有前提条件,就是在处理对象的过程中除了构造和析构是不会被改变的。
std::async是C++11标准引入的函数模板,它用于异步执行某些任务,通常在单独的线程或者线程池中运行,它会返回一个std::future用于等待和获取异步执行的结果。
为什么这里说需要谨慎使用呢?其实原因上面一句话也提到了,就是它可能是在单独的线程中运行的。那么躲过我们想并发执行多个异步任务,会导致系统产生多个线程,执行完任务后退出。熟悉操作系统的朋友应该知道,创建线程的操作是非常耗时的,它需要让系统进入到内核,并且执行很多进程和线程相关的操作,另外过多的线程并不能真正的做到异步,因为我们的CPU的执行单元是有限的。所以调用std::async是应该谨慎一些的。
接下来让我们看看三大编译器的std::async的实现:
首先来看GCC:
https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/std/future
// Shared state created by std::async(). |
很显然使用了std::thread创建新线程。
然后再来看Clang:
https://github.com/llvm/llvm-project/blob/main/libcxx/include/future
template <class _Rp, class _Fp> |
同样的,采用了创建新线程的方法。
最后来看看MSVC提供的STL的实现:
https://github.com/microsoft/STL/blob/main/stl/inc/future
template <class _Rx> |
可以看到,微软提供的std::async的实现好了一些,它使用了线程池来进行异步操作,这样效率会好不少。值得一提的是,这里使用的是微软提供Parallel Patterns Library (PPL)库,专门用于多线程和并行计算的,和Intel的TBB比较类似。
由此可见,如果需要大量使用异步操作执行任务,依赖std::async的效率是不太可靠的,我们最好是能够使用更高效的线程池的方案。
我在大学里学C++的时候,印象最为深刻的是老师反复告诫我们,应该如何传递函数参数。为了避免发生不必要的内存拷贝和复杂的对象构造,一般来说对于复杂对象都会采取使用传递引用的方式,当然如果参数不会被改变,最好使用常量引用,只有一些基础类型可以通过值传递参数。
按照上述方式写代码确实不会任何问题,不过C++向来是一门追求极致的语言,在效率方面更是如此,所以在C++17引入了std::string_view,并且推荐使用值传递的方式作为参数来传递,例如:
size_t ret_sv_byval(std::string_view sv) { return sv.size(); } |
上面的代码通过值来传递std::string_view,而不是通过引用,下面我们就来探讨为何这里更加推荐使用通过值来传递参数。
首先,也是最容易理解的一点,能够使用值传递std::string_view必然是因为它足够简单。它的典型的实现只有两个成员:指向常量字符串的指针和字符串大小。值得一提的是,std::string_view并不是C++17才出现在我们视野中的,实际上在chromium和llvm中,早就出现了类似的实现。在C++标准的草案也可以追述到2012年的n3442,当时std::string_view还被称为string_ref。后来到了2014年,经过了大约7个版本的修订,才有了我们今天看到的std::string_view。
我们当然不能因为std::string_view足够简单认为使用传值的方式比传递引用的方式高效,这需要我们拿出其他的证据。
我们都知道,对象的拷贝是在caller中发生的,例如下面这两行代码:
size_t ret_str_byref(const std::string& s) { return s.size(); } |
在使用-O2的优化选项进行编译的情况下,他们生成的汇编代码是相同的,都是:
ret_str_byref: |
因为临时对象的拷贝在调用者函数中发生,所以这里不会有任何区别。可以看到,这里都使用了内存访问,访问了rdi+8的数据。这里如果我们使用std::string_view会如何呢?
size_t ret_sv_byval(std::string_view sv) { return sv.size(); } |
对应的汇编代码为:
ret_sv_byval: |
显然,这里直接使用了寄存器,没有涉及到任何内存的访问,这样访问效率必然是有所提升的。
引用的另一个劣势是,在一个不需要涉及内存的操作中,因为引用语义和内存相关,导致编译器会强行将对象设置在内存中,来看看下面这个例子:
size_t sv_call_val(std::string_view sv) {return ret_sv_byval(sv);} |
这两个函数非常简单,直接使用参数调用后续函数,不过编译后的代码截然不同:
sv_call_val |
可以看出,前者可以直接执行jmp,跳到目标函数。后者,也就是穿引用的函数,则是需要先将数据写到栈上,然后在调用函数,显然前者的效率更高。
程序的编译优化并不是容易的事情,编译器要考虑非常多的因素,例如外部对内部的影响等。传值和传引用的区别在于,传递引用的对象可能会被其他外部因素干扰导致编译器没办法进行优化,但是传值就不存在这样的问题,因为传值是拷贝,不会被外部影响,编译器优化起来更加得心应手,来看看下面的代码:
size_t ret_sv_byval(std::string_view sv, size_t& troublemaker) { |
上面两个函数唯一的区别就是sv是传值还是传引用,看似没有太大区别,但是我们来看看汇编代码:
ret_sv_byval |
可以看到,前者就是简单了一条寄存器操作就返回了,temp和troublemaker都没有给函数带来任何影响。而后者就完全不同了,因为传递的是引用,即使是常量引用,也导致编译器无法对代码进行优化。因为对于编译器而言,并不知道troublemaker是否会对sv的内部有所影响,只能按照代码进行编译。
至此,我们可以得到结论是,对于简单对象,例如使用寄存器就能传递其数据的对象,我们可以使用传值的方式传递参数,例如简单的std::pair,std::span等等。当然比较复杂的对象,还是要使用传递引用的方式的。
在oneAPI的一系列的产品中,我首先要介绍的是DPC和它的编译器,因为这部分内容十分有趣。我们都知道,一个程序运行效率高低,跟语言本身和他的编译器是息息相关的,比如我们不能指望python的程序在算法和运行环境相同的情况下跑过C和C的程序。
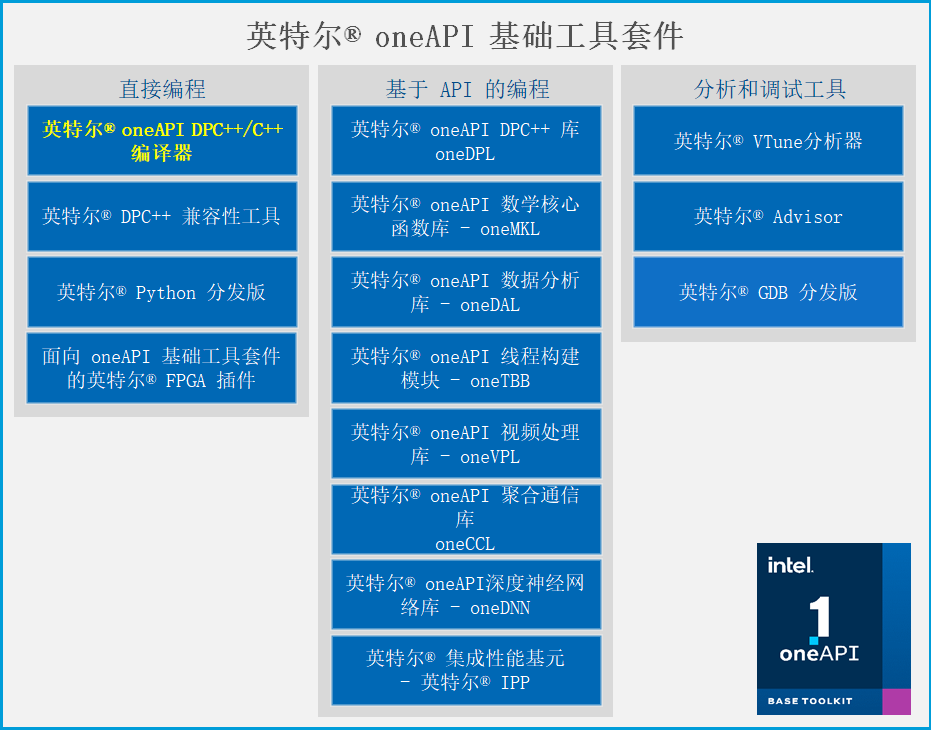
Intel的DPC团队当然考虑到了这一点,DPC和他的编译器正是基于高效的C语言以及时下先进的编译器clang/llvm的。在llvm的支持下,让DPC能够轻松的在不同的平台上使用。
DPC是基于标准C和SYCL的,也就是说,我们可以用C一种语言来编写各种加速平台的程序,这样就让程序员能脱离学习专属语言的麻烦。至于SYCL标准,DPC实际上在它的基础上也做了比较多的优化,方便程序员编写代码。
因为DPC++的编译器是基于clang/llvm的,所以它也是一个开源的编译器,我们可以在Github上找到他的源代码。并且通过翻阅提交记录来初步了解编译器是怎么构建起来的,总的来说这是一个在前中后端都有进行开发的编译器。
oneAPI还提供了一套兼容性工具,这套工具可以将CUDA编写的代码转换为标准的c代码,便于使用DPC进行编译。不过需要注意的是,并不是所有的代码都可以。CUDA代码大约可以有90%到95%能够正确的转换为DPC++的代码,当然剩下的一部分会注释留白,让开发人员进行转换。这个转换工具会尽可能的转换出开发人员可读的源代码程序。
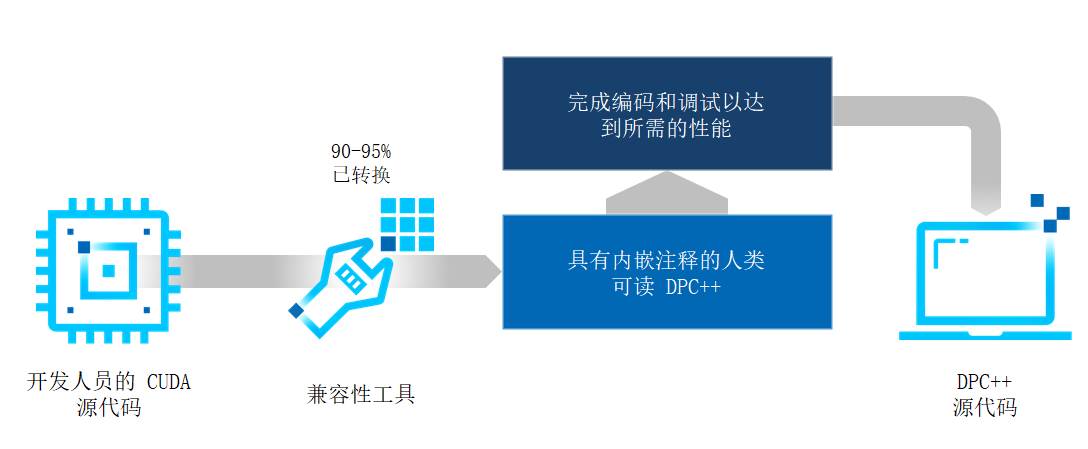
感兴趣的朋友可以访问以上链接,这里有非常详细的代码和操作例子。
再来说一下oneAPI提供的API,使用API可以让除了C以外的语言也享受到oneAPI提供的强大的高性能计算功能。例如,DPC库,这个还是基于的C++,它是优化了C++标准算法,包括并行算法等,并且能够保证在不同的硬件平台上高效运行。另外,为了让开发人员快速学习,它基于的是pstl和boost.compute库。再例如oneDNN这个库,主要就是用来做深度学习框架的,在oneAPI里提供的tensorflow的底层就是由oneDNN做的支持。
oneAPI提供的库有很多,有兴趣的朋友可以直接上官网查看,会有非常详细的介绍。其实在了解oneAPI之前,我就用过这其中的TBB库,这是一个做并行编程和多线程的库,和微软的PPL很像。简单来说就是在使用这个库的时候,我们不需要关心线程本身,也不需要关心硬件环境使用多少线程效率最高,如何做线程调度效率最高,直接把任务扔到接口就行了,非常方便,即使不编写高性能计算程序的朋友也可以去了解一下。
要介绍的最后一部分是分析和调试工具,这一部分中的GDB,我想大家再熟悉不过,不过oneAPI提供的GDB是有一些不同的,它除了能调试普通程序,还支持通过双机来调试异构程序。也就是说,它可以调试到设备内核代码中。请注意,这里的内核不是指操作系统内核,而是在加速设备上执行代码。使用普通的调试器是无法做到这一点的,虽然看起来都像是C++的代码,但其实编译出的程序并不是像主机端的代码一样可调的。大家也可以试一试,如果使用普通的调试器对内核代码下断点,跑起来的程序是肯定不会中断下来的。
第二个工具是Advisor,这个工具可以对异构程序进行分析,并且提供优化建议,包括怎么使用内存,怎么使用多线程,怎么使用并发。这个工具我是用的不多,有兴趣的朋友还是可以看官方文档。
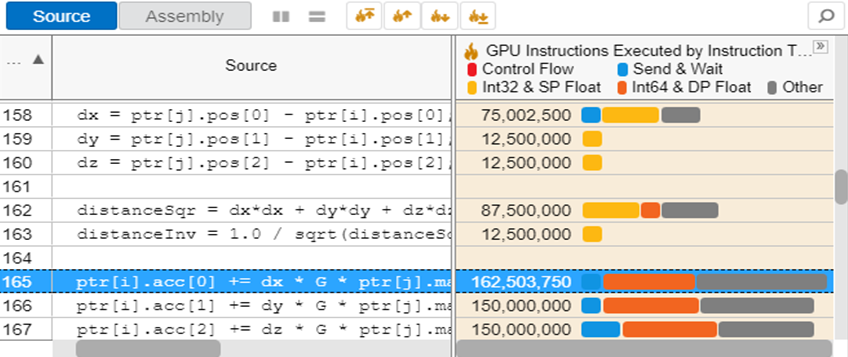
第三个工具是Vtune,这个工具就厉害了,我想做过性能优化的朋友肯定是用过的。这个工具在做性能优化方面并不局限于异构程序,其实很早之前我就接触过它了。它可以对程序性能的缺陷做非常系统的分析,包括IO,线程、内存、指令集的使用等等,分析的粒度可以从指令到代码行再到函数块,支持的架构从CPU、GPU到FPGA,总之做性能优化的朋友千万不要错过这个工具。
以上就是对Intel oneAPI的一个大概的介绍,想了解更多信息还是要访问官网,另外,如果有朋友想进一步的做实验,Intel还提供了DevCloud这样一个免费的实验平台给大家,有兴趣的朋友不妨一试。