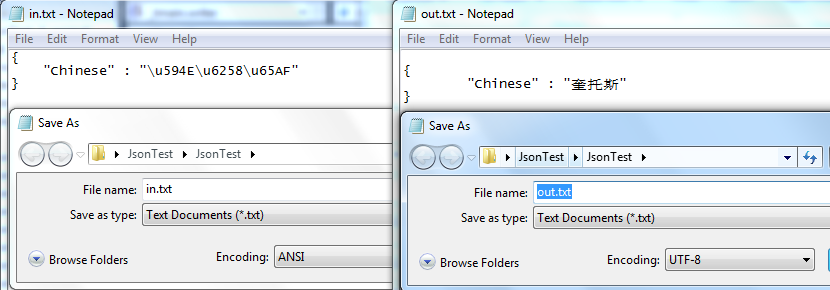
最近工作中用到了jsoncpp来解析json文件。但是遇到了一个这样的问题,如果json代码中有中文,并且用“\u594E\u6258\u65AF”这样的方式表示,那么jsoncpp解析的时候,就会把他转换成UTF-8。到这一步还是OK的,然后我就试图把这段中文写回文件,问题就来了,jsoncpp不会把中文转换为“\u594E\u6258\u65AF”这样的形式在存储,而是直接存储为UTF-8格式的文件。如图所示:
而我恰好是需要这种经过编码的形式的字符串,而非直接给我中文。在网上搜了搜,貌似也没有很好的解决方案,只好自己修改jsoncpp的代码以满足这个需求了。http://en.wikipedia.org/wiki/UTF-8 上很清楚的描述了这些转换关系,所以完全可以自己动手写一个这样的函数。以下是我自己的实现:
static int UTF8TocodePoint (const char *c, unsigned int *result) int count = 0 ;if (((*c) & 0x80 ) == 0 ) {*result = static_cast <unsigned int >(*c); count = 1 ; } else if (((*c) & 0xe0 ) == 0xc0 ) {*result = static_cast <unsigned int >((((*c) & 0x1f ) << 6 ) | ((*(c + 1 )) & 0x3f )); count = 2 ; } else if (((*c) & 0xf0 ) == 0xe0 ) {*result = static_cast <unsigned int >((((*c) & 0xf ) << 12 ) | (((*(c + 1 )) & 0x3f ) << 6 ) | (((*(c + 2 )) & 0x3f ))); count = 3 ; } else if (((*c) & 0xf8 ) == 0xf0 ) {*result = static_cast <unsigned int >((((*c) & 0x7 ) << 18 ) | (((*(c + 1 )) & 0x3f ) << 12 ) | (((*(c + 2 )) & 0x3f ) << 6 ) | (((*(c + 3 )) & 0x3f ))); count = 4 ; } else if (((*c) & 0xfc ) == 0xf8 ) {*result = static_cast <unsigned int >((((*c) & 0x3 ) << 24 ) | (((*(c + 1 )) & 0x3f ) << 18 ) | (((*(c + 2 )) & 0x3f ) << 12 ) | (((*(c + 3 )) & 0x3f ) << 6 ) | (((*(c + 4 )) & 0x3f ))); count = 5 ; } else if (((*c) & 0xfe ) == 0xfc ) {*result = static_cast <unsigned int >((((*c) & 0x1 ) << 30 ) | (((*(c + 1 )) & 0x3f ) << 24 ) | (((*(c + 2 )) & 0x3f ) << 18 ) | (((*(c + 3 )) & 0x3f ) << 12 ) | (((*(c + 4 )) & 0x3f ) << 6 ) | (((*(c + 5 )) & 0x3f ))); count = 6 ; } return count;}
然后把这个函数的调用加入到valueToQuotedString中,将原始的代码:
if ( isControlCharacter ( *c ) ){ std::ostringstream oss; oss << "\\u" << std::hex << std::uppercase << std::setfill ('0' ) << std::setw (4 ) << static_cast <int >(*c); result += oss.str (); } else { result += *c; } break ;
修改为:
if ( isControlCharacter ( *c ) ){ std::ostringstream oss; oss << "\\u" << std::hex << std::uppercase << std::setfill ('0' ) << std::setw (4 ) << static_cast <int >(*c); result += oss.str (); } else if ((*c) & 0x80 ) {unsigned int num = 0 ;c += UTF8TocodePoint (c, &num) - 1 ; std::ostringstream oss; oss << "\\u" << std::hex << std::uppercase << std::setfill ('0' ) << std::setw (4 ) << static_cast <int >(num); result += oss.str (); } else { result += *c; } break ;
这样还没算结束,因为这个函数开头的地方还有一个判断,我们也需要修改一下,将原始代码:
if (strpbrk (value, "\"\\\b\f\n\r\t" ) == NULL && !containsControlCharacter ( value ))return std::string ("\"" ) + value + "\"" ;
修改为:
if (strpbrk (value, "\"\\\b\f\n\r\t" ) == NULL && !containsControlCharacter ( value ) && !containsMultiByte ( value ))return std::string ("\"" ) + value + "\"" ;
containsMultiByte的实现是这样的:
static bool containsMultiByte ( const char * str ) while ( *str ){ if ( ( *(str++) ) & 0x80 )return true ;} return false ;}
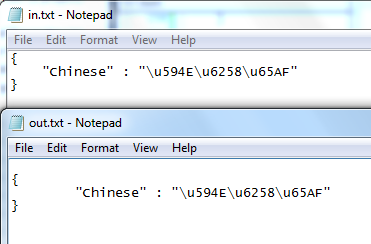
好了,万事俱备,现在试一试效果,结果如图:
现在这个jsoncpp看起来已经满足了我的需求,但是不确定的是,不知道这样修改会不会引起其他问题。现在也只能说暂时不去管他,有问题再一步一步的修改吧。