利用mnist数据对数字符号进行识别基本上算是深度学习的Hello World了。在我学习这个“hello world”的过程中,多多少少有点不爽,原因是无论是训练数据还是测试数据,都是mnist准备好的,即使最后训练的数字识别率很高,我也没有什么参与感。其实,我特别想测试自己手写数字的识别率。
为了完成上述想法,我第一个想到的是将普通图片数据转换成mnist数据。mnist的数据格式非常简单,如下图所示:
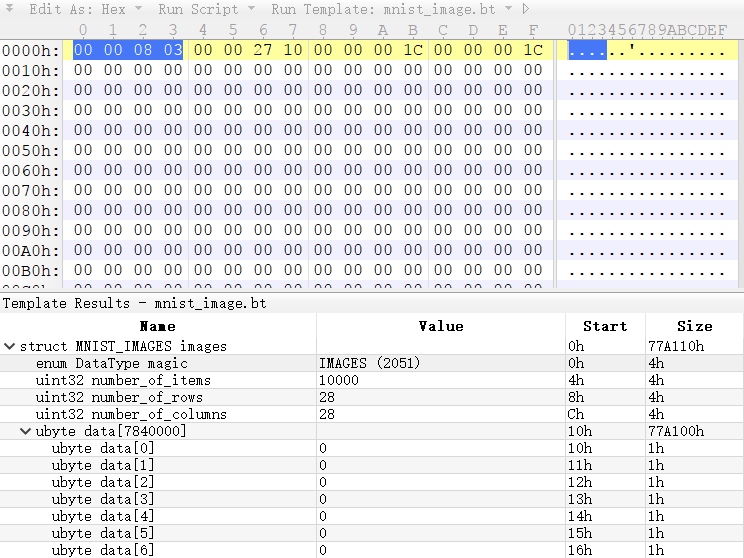
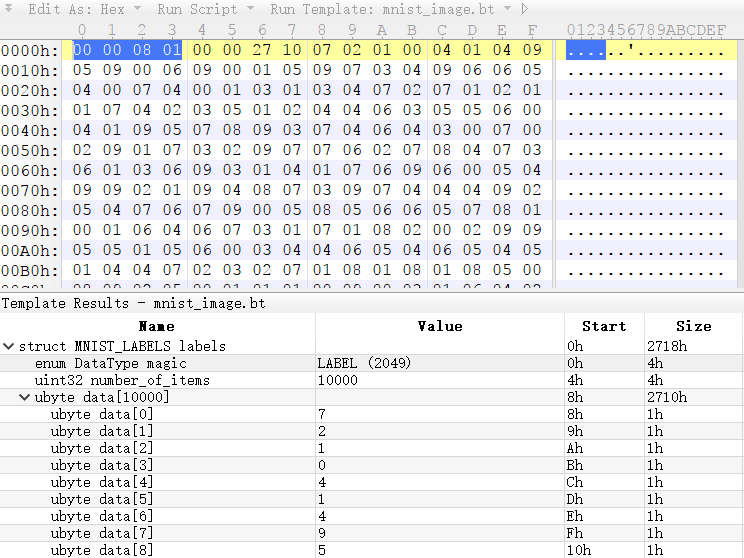
两幅图分别表示了图形数据和标签数据。他们都有一个4字节长度的magic number,用来识别数据的具体格式。如果是标签数据,那么格式相对简单,后续是一个标签数量,接着的是标签数据(0-9的值)。如果是图像数据,那么magic number后,出了4个字节的数据数量以外,还有分别占4字节的行列数据,最后的就是图像数据。结构非常简单,但是值得注意的事情有两点:
- 数据使用big endian组织的。
- 图像数据中,255表示前景,也就是黑色,0表示背景,也就是白色,这和我们平时看到的RGB是不同的。
知道了数据格式,接下来的事情就是用程序将图像转换到mnist了。说实在的,如果对于操作二进制的数据,C比python还是方便不少的。但是C读取图像更加麻烦。所以这里推荐还是使用python对数据做转化。
# 首先导入图像处理库 |
以上是对图像数据的转换,标签数据的转换代码和以上代码基本一样,所以这里不再赘述。
有了这个方法,我们可以通过画图软件画上一堆自己手写的数字,通过python批量转化成mnist格式的数据,再让tensorflow进行测试,算出模型对我们自己手写数字的识别正确率。
好了,以上就是我说的第一种让模型识别自己的手写数字的方法。不过,这个方法不能实时的识别我手写的数字,让人总觉得缺点什么。于是就有了第二种方法,这种方法将借助浏览器,js以及web server等工具将手写的数字实时的传给后台的模型进行识别,然后把结果回复给用户。不过这个方法就要等待下一篇文章来描述了。