everythings是一个非常强大而且好用的文件搜索工具。他搜索文件的速度非常之快,基本上刚刚输入要查找的文件名,文件已经搜索了出来。这里就简单介绍一下他的工作原理。
有一点已经非常明显,everythings在查找工作开始之前会建立全盘文件索引的数据库,那么这个数据库必然就是搜索文件快速的最重要的原因。而这个数据库的建立的用时似乎非常之短,是普通方法下遍历整个卷所不能及的。
实际上,建立数据库的方法确实比较特殊。简单来说就是遍历目标卷NTFS文件系统的Master File Table(简称MFT)的记录,这也解释了为什么everythings只能工作在是NTFS的文件系统的卷上。MFT可以看成ntfs中文件的索引,MFT中的每条记录都是指向卷中的一个文件。遍历这个索引的速度可要比按照目录递归整个卷的速度要快得多了。不过可惜的是,Windows并没有提供能够直接访问MFT的API,除非你直接解析NTFS磁盘格式(参考这篇文章)。而且就算让你直接遍历的MFT,要监控文件的变化并且写入数据库也是一个不好办的工作。不过可喜的是,微软提供了一种间接遍历MFT记录的方式,并且通过这样的方式可以监控卷上文件的变化,他就是Change Journal(官方文档)。
Change Journal实际上是Windows 2000的NTFS文件系统就提供了的功能。其目的就是如同名字一样,记录文件改变的日志,方便NTFS文件系统对文件的恢复,这确实是个不错的特性。如何使用这个功能去遍历和监控MFT的记录,我这里就不做详细介绍了。因为有一片更加好的文章已经写的非常的清楚,我的demo也参考了他的很多代码。这篇文章叫做《Keeping an Eye on Your NTFS Drives: the Windows 2000 Change Journal Explained》是1999年9月份的msdn杂志发表的。
我这里假设你已经阅读了这篇文章。我们已经知道了遍历和监控MFT记录的方法,并且通过这个方法获得了每个文件的文件名,file reference和parent reference(可以理解为文件id和其父目录id)。那么这里就可以把这三个元素作为一条记录存储在我们制定的数据库中。
下面简单说下如何利用这个数据库,当需要查找文件的时候:
1.获得用户输入的文件名。
2.通过文件名A可以从数据库中筛选出一些记录,而这些记录中就包括了文件的parent reference。
3.通过parent reference再次查找数据库的file reference字段,获得对应的文件名B,这个文件名B就是文件A的父目录了。重复这一步直到根目录为止。
这样就能找到文件的详细路径了。
我写demo的时候并没有考虑怎么构建这个数据库,直接用了sqlite。不过如果能自己设计一个专门为存储这些数据的小数据库,也应该有更高的效率吧。everythings的数据库就是经过bzip压缩的自定义的文件。
DEMO——构建文件索引数据库:
DEMO——查找文件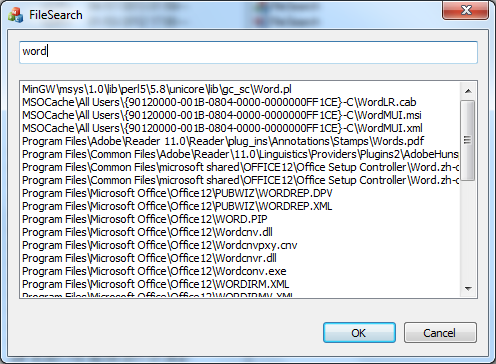
P.S 如果采用sqlite作为文件数据库的话,建立索引的插入数据操作一定要利用sqlite的事务机制,否则会在插入数据上花费很多时间。
P.S.2 everythings之所以需要管理员权限才能工作,是因为他需要打开本地卷的句柄,这个就需要管理员权限了。
最后说一点这种方法的不足吧。那就是这种方法对于有多个hardlinks的文件,只能枚举出一个路径。关于hardlink的介绍可以参考这篇文章。由于这个不足,你在查找system32下的文件的时候,往往搜索不到,搜索到的又往往在其他目录,出现尤其多的应该是Winsxs目录了(而关于Winsxs可以看看这篇翻译,翻译质量很不错)。例如我们搜索C盘下的notepad.exe,everythings搜索的结果是这样的: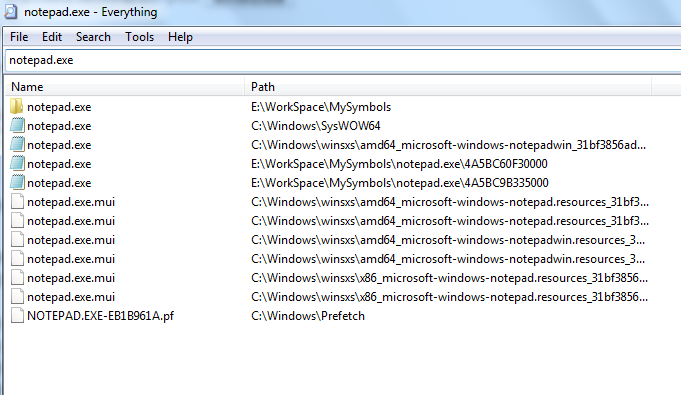
可以注意到并没有system32下notepad.exe的身影。我们的demo同样也会遇到这样的情况: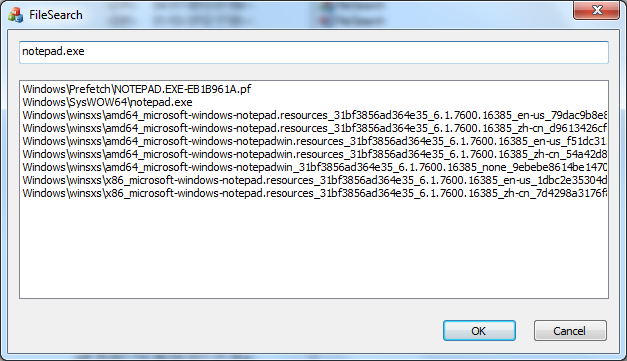
下图显示的是同一个notepad.exe的4个存储位置。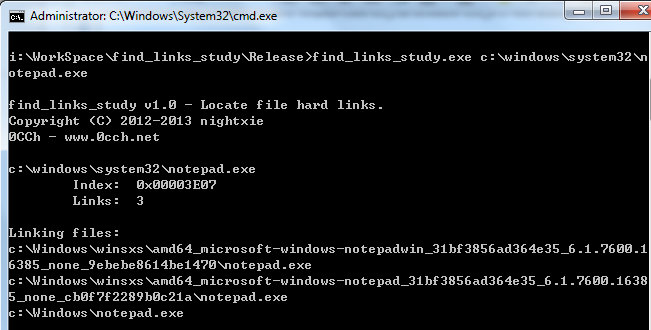
虽然everythings有这样的一个不足,但是瑕不掩瑜,他的的确确是一个非常非常优秀的工具!我这里探讨的也仅仅是他的大概原理。实际上这个工具如此优秀,必然是在很多细节上做的非常好才行的。强烈推荐大家使用!