自从有tensorflow这样的平台工具横空出世,机器学习的代码编写逐渐变的平民化了。我们不需要太多的数学理论知识就能够完成一些机器学习的项目。比如在使用tensorflow的时候,我们只需要定义好损失函数,tensorflow会自动的帮我们完成反向传播改善参数。我们所需要做的就是合理利用tensorflow创建模型。
当然,我并不是在鼓动初学者跳过数学原理部分,而是认为,如果没有数学基础,入门就死磕原理容易产生挫败感导致放弃。这样就不如先接触简单的项目,在有了一定的体会后,再回头去看看数学原理的东西,这样会更容易接受。比如,当能用tensorflow完成对mnist的训练之后,再去理解反向传播这四个公式,应该会更有感觉。
接下来相信看看这份代码
# -*- coding: utf-8 -*- |
step1:read_data_sets是tf提供读取mnist数据的函数,运行时会有函数过时的警告提示,但是不用管它,因为用起来完全没有问题。one_hot参数在这里很重要,他将实际的标签值转化为一个向量,例如,将标签值3,转化成表示0-9是否置位的向量:\( \left(\begin{array}{cccccccccc}0;0;0;1;0;0;0;0;0;0;\end{array}\right)^T \)
step2:创建权重和偏置,创建方法有很多,我用的是期望为0,标准差为0.1的随机分布。
step3:创建输入层和标签的placeholder,大概的意思是占住空间,以方便后续数据喂给模型。
step4:实际上是向前传播 \( z = w^{T}x,+,b\),\( a = sigmoid(z)\),其中sigmoid是\( \frac{1}{1+\exp(-z)}\)。这里可能有一个疑问,第二个隐藏层到输出层,没有使用sigmoid函数。原因继续往下看就知道了。
step5:计算损失函数,调用了tf的sigmoid_cross_entropy_with_logits,这个函数把交叉熵和sigmoid的计算放在了一起,所以上面不需要去计算sigmoid了。这样做的好处很明显,就是方便我们修改从最后一个隐藏层到输出层的激活函数,比如将sigmoid_cross_entropy_with_logits替换为softmax_cross_entropy_with_logits,那么我们最后一个激活函数就变成了softmax。最后设置学习率并且把我们的损失函数传给梯度下降类的最小化函数中,tf就会自动的帮我们优化参数,从而最小化损失值了。
step6:使用测试数据去计算模型的识别准确率
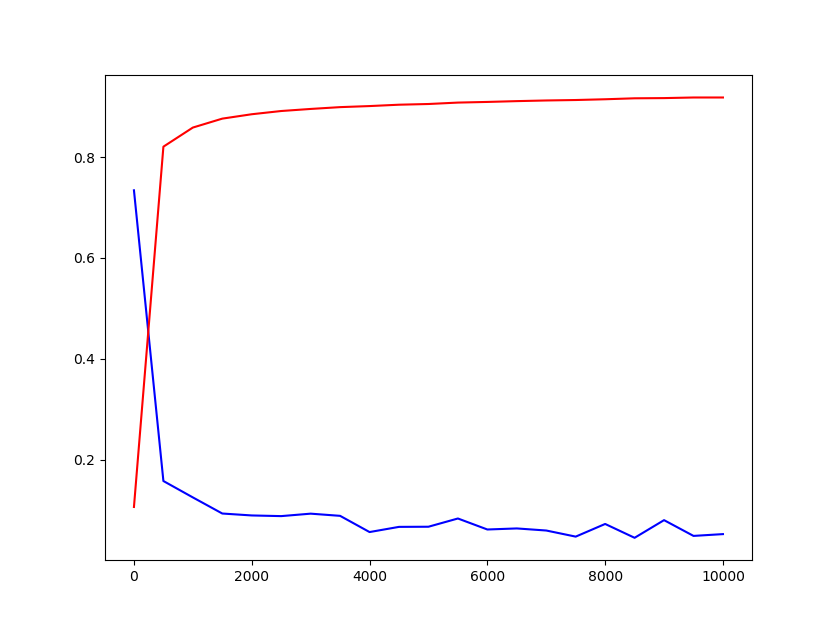
step7:最后一步,我们将数据分为小份,随着迭代,逐步喂给模型。然后记录损失和准确率的变化,并做图。
这里我们为了简单,没有使用softmax,dropout和正则化等优化方法,所以识别率只达到了90%,不过作为一个入门来说已经够了。