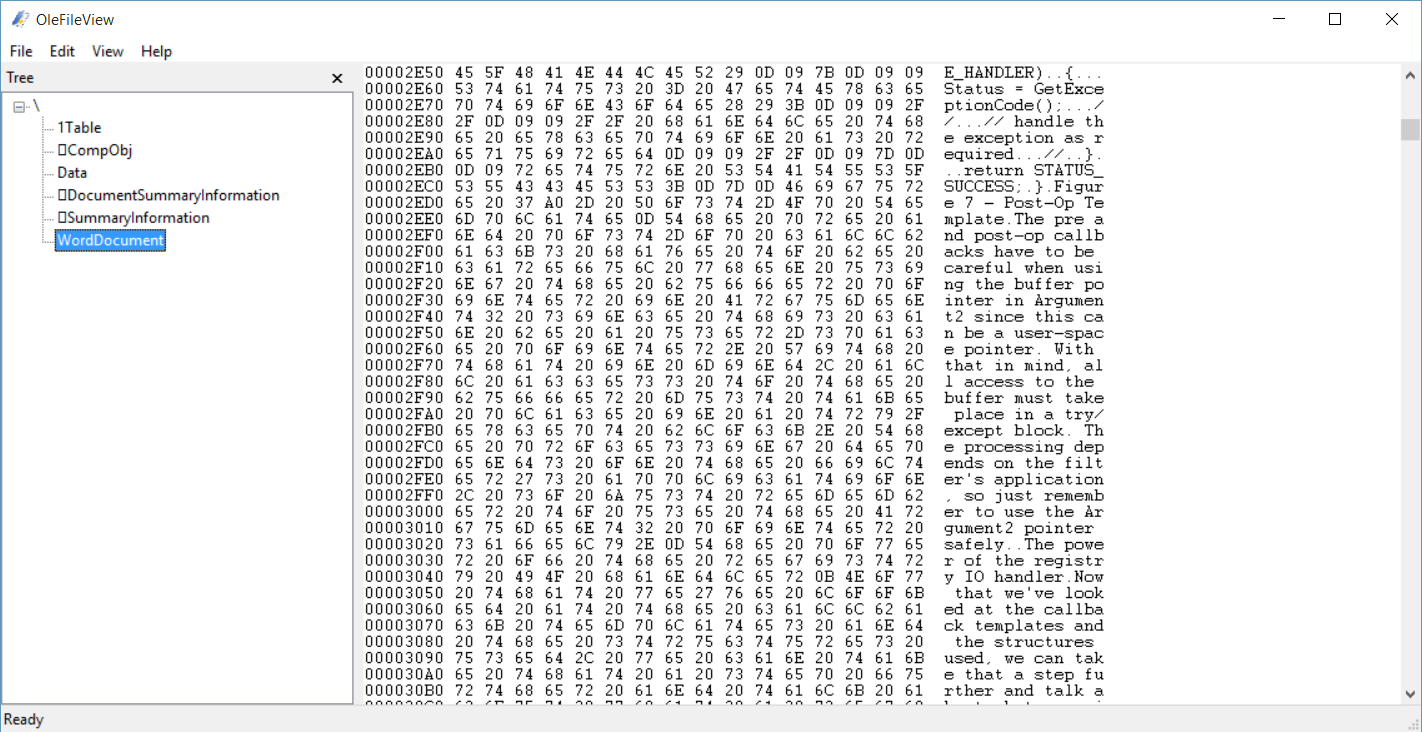
OleFileView是一个查看结构化存储文件的工具,我们熟悉的Ole存储的文件就是这种格式,虽然很老了,但是依旧被广泛使用,例如老版本Office的文件doc,xls等,包括msi,jumplist等,都是采用的这种格式。
所以我也就抽了点时间研究了一下这个数据结构,可以说这就是个小型的文件系统,虽然比不上NTFS,但是对于一般的存储可以说是小菜一碟。
OleFileView是一个查看结构化存储文件的工具,我们熟悉的Ole存储的文件就是这种格式,虽然很老了,但是依旧被广泛使用,例如老版本Office的文件doc,xls等,包括msi,jumplist等,都是采用的这种格式。
所以我也就抽了点时间研究了一下这个数据结构,可以说这就是个小型的文件系统,虽然比不上NTFS,但是对于一般的存储可以说是小菜一碟。
Windows Management Instrumentation (WMI) 是微软实现的一套可以通过网页管理计算机的系统,我们可以通过WMI查询计算机的方方面面。从Vista开始,这个机制增加了Instance Event的提醒机制,这个机制可以帮助我们监控各种Instance的创建、删除和修改。所以,我们可以想到的是进程也是在WMI里的Win32_Process有Instance的记录,这样我们就可以跟踪到进程的创建和结束了。当然,我们还可能监控到文件等等WMI里的各种Instance。下面是一个监控进程的例子:

最近看到有些恶意程序,从网络上下载PE文件后,直接放在内存里重定位和初始化,为了能将其dump出来,所以写了这个Windbg脚本。
.foreach( place { !address /f:VAR,MEM_PRIVATE,MEM_COMMIT /c:"s -[1]a %1 %2 \"MZ\"" } ) |
上周终于下定决心把blog从wordpress转到jekyll,不是因为wordpress臃肿,也不是因为jekyll的更加Geek,纯粹是因为穷。我一直都觉得wordpress是一个非常伟大的blog程序,虽然臃肿了点,但确实功能强大操作简单,对于我这种懒人和对前端代码完全不熟的程序员来说,wordpress确实是一个非常好的选择。但是问题就出在了webhost上,我使用的webhost刚刚买的时候是50多刀一年,之后每年涨价,今年续费看了下需要100刀左右,这个确实让我心中无数的羊驼奔腾了起来。于是就决定把blog搬离这个地方。
刚开始我只是想找便宜的地方转移wordpress的blog。网上也有很多这类的webhost,第一年进去都很便宜,甚至有1刀一个月的。但是一朝被蛇咬啊,为了防止以后又被迫搬家,于是打消了这个念头。想要便宜和稳定的blog空间,看来是只有伟大的Github。而Github只支持静态程序,那么我也只能放弃wordpress的方便,自己折腾点静态博客程序了。摆在眼前的选择其实很多最基础jekyll,加强版的octopress以及hexo。第一个程序的优点就是简单基础,缺点就是太基础了,而octopress在jekyll的基础之上加上了一些插件,让blog默认的功能变得丰富起来。之后hexo,也是一个自带很多基础功能的程序而且还带了很多非常漂亮的主题,主题控的bloger不妨选择这个,我就特别喜欢他其中的一个默认主题,但是折腾样式的时候jekyll的基本结构都搭建好了,所以就没有更换hexo程序,于是极度痛苦的折腾了一周的css和ruby插件才把现在的blog折腾的和之前的差不多。
简单说下用jekyll在Github上搭建blog的步骤,其实网上很多很多教程,这里记录下就是防止自己忘了把。
这样,最基础功能的blog就搭建好了,接下来就是把blog从wordpress转移到jekyll了。方法是使用exitwp这个python脚本。
这样我们看到的就是一个最简单的jekyll的blog,要想改变主题,自己去折腾吧。我能做的就是推荐两个jekyll的插件,分别是按日期和分类生成归档网页的,可以在我的Github上看到。
最后要说的是rouge语法高亮有个bug,在使用显示行号linenos参数的时候会出现嵌套错误的问题,解决方法倒是有,不过有了行号之后高亮的显示极其丑陋,所以还是我还是没用这个参数。如果有需求可以使用代码rouge_linenos_patch.rb覆盖”\lib\ruby\gems\2.2.0\gems\jekyll-2.5.3\lib\jekyll\tags\highlight.rb”里对应的函数即可。
自从Windows XP SP2开始,微软对文件加入了Zone.Identifier的数据流,所以这个也不算什么新东西了,最近偶然有机会研究了下所以就记录了下来。
说起Zone.Identifier,我们最常见的应用就是在我们从Internet上下载了可执行文件后,运行的时候会弹出如下图的警告窗口:
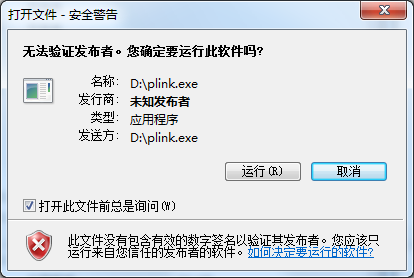
弹出这个窗口就是因为Explorer在运行这个文件的时候先检查了Zone.Identifier的数据,发现了如下文本
[ZoneTransfer]
ZoneId=3
这个ZoneId=3,就是指明这个文件是由Internet上下载的。根据MSDN,这个id有以下几种:
|
查看这个数据流的方法也很简单,用notepad就行了。
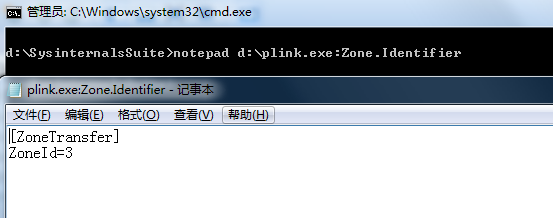
另外如果想给添加或者去除这个数据流,我们这里有两种方法:
1.直接读写数据流,其实这个跟普通文件读写没什么两样。
2.调用微软提供的com接口,这个比较是规范的。
对于第一种方法,没什么可说的,无非就是文件操作的那些API。第二种方法我们需要用到以下两个接口:
IPersistFile
IZoneIdentifier
我们先创建IZoneIdentifier接口,然后query出IPersistFile打开文件,最后读取或者写入文件。
代码详见:http://blogs.msdn.com/b/oldnewthing/archive/2013/11/04/10463035.aspx
最后说一下,之所以能有Zone.Identifier这种功能,完全依赖于NTFS文件系统,它允许多个数据流的存在,对它而言,每个数据流无非就是一个属性而已,只不过Zone.Identifier是一个名字为Zone.Identifier的数据流,而文件本身的数据是一个没有命名的数据流而已。用ntfs_study查看,如下图,第一个Data数据没有名字是文件本身的数据,第二个就是Zone.Identifier的数据了。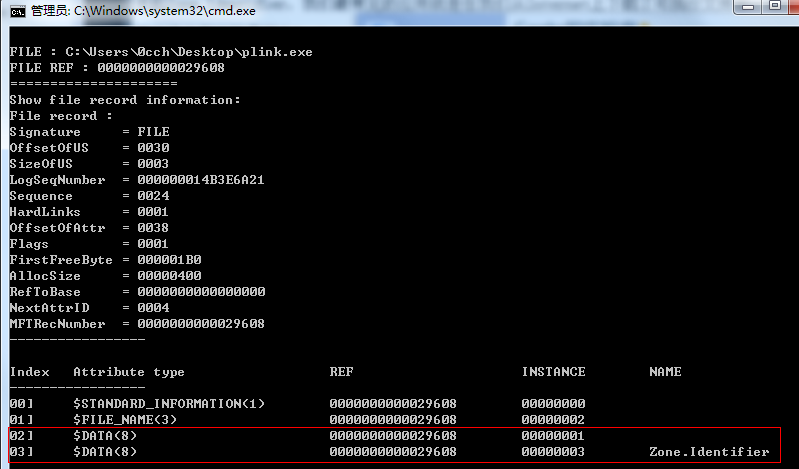
在Windows 8下,多了一套很有趣的API,SpellChecking,这套API的作用也是一目了然,是做拼写检查的。这么有趣的一套API怎么能不写个程序玩玩呢,于是我写了个小程序,看了看对英文拼写检查的效果,如图。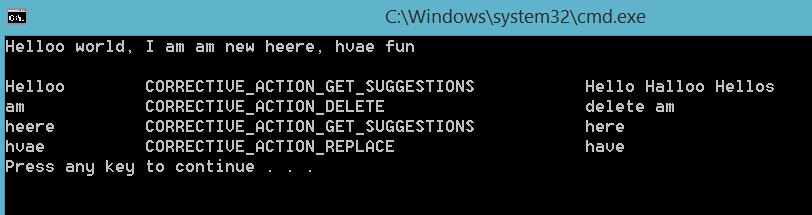
拼写检查会给出三个结果,分别是删除,替换和建议,根据不同的结果我们可以调用不同的接口来获得最佳的体验。代码如下:
// SpellCheck.cpp : Defines the entry point for the console application. |
我们在创建或者打开对象的时候需要指定ACCESS_MASK,有的时候为了方便,我们会在ACCESS_MASK的参数中填GenericRead,GenericWrite这样的值,那么对于这些对象来说,这些GenericXXX究竟是什么样的ACCESS_MASK都是保存在对象的GenericMapping中,以下就是Windows 8.1中所有对象的GenericMapping了。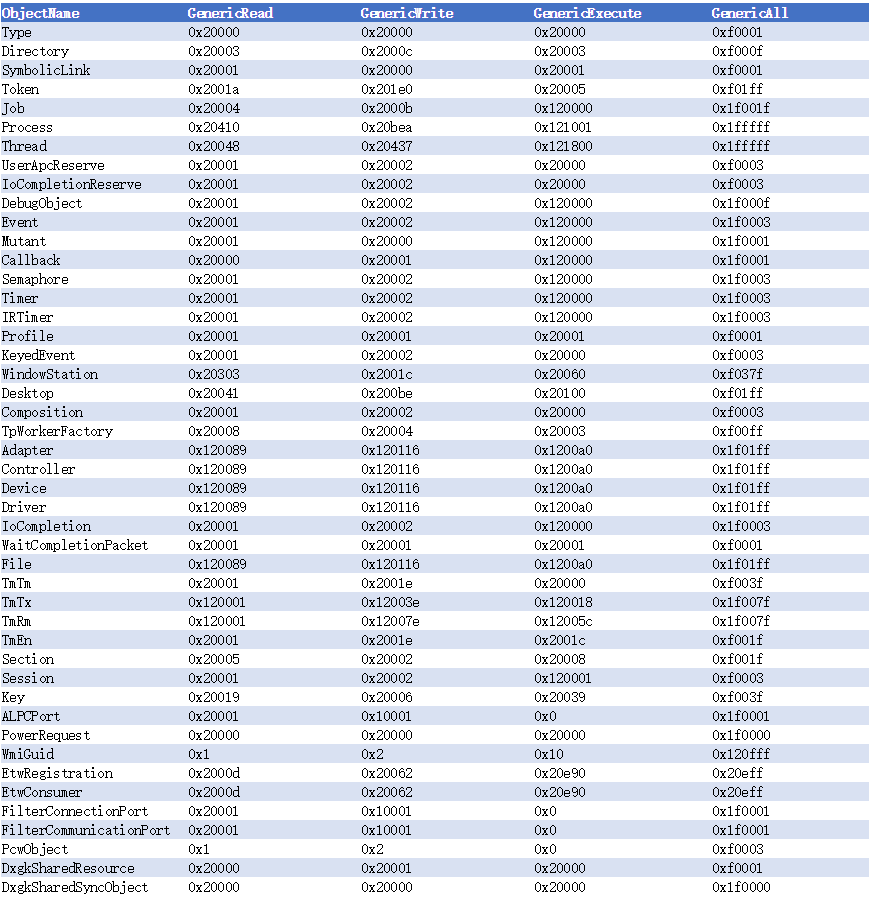
将ACCESS_MASK数字转换成我们看得懂的宏,可以使用我写的一个小网页:
http://0cch.com/accessmask.html
我们都知道SetWindowsHookEx可以设置全局钩子,让自己的dll注入到有窗口的进程中去。注入原理就不再赘述了,网上资料很多,简单看一下调用堆栈方便我们说明怎么去防注入。
kernel32!LoadLibraryExW
USER32!__ClientLoadLibrary
ntdll!KiUserCallbackDispatcher
nt!KiCallUserMode
nt!KeUserModeCallback
win32k!ClientLoadLibrary
win32k!xxxLoadHmodIndex
win32k!xxxCallHook2
win32k!xxxCallHook
win32k!xxxCreateWindowEx
win32k!NtUserCreateWindowEx
nt!KiFastCallEntry
ntdll!KiFastSystemCallRet
ntdll!KiUserCallbackDispatcher
USER32!NtUserCreateWindowEx
USER32!_CreateWindowEx
看着个堆栈,防注入的方法这里就可以大概说出三种:
第一个方法其实也谈不上方法,也就是说控制台程序就不用担心这些了。第二个方法需要是否是判断自己的模块,这个方法也挺麻烦的,因为你得放过一些不是自己的模块,比如微软的模块。所以这里重点说第三个方法,我们去Hook __ClientLoadLibrary,这样我们就只是避免了全局钩子的注入了。这里我们不用去Inline Hook该函数,Inline Hook比较麻烦。我们的做法是修改user32!apfnDispatch这个数组,直接替换对应于__ClientLoadLibrary所在位置的值。这样摆在我们面前的稍微麻烦一点的事情有两个,一个是确定数组开始的地址,第二就是确定__ClientLoadLibrary在数组中的index。
那么分别来解决这两个问题:
组数的位置
其实就是PEB的KernelCallbackTable,虽然PEB没有文档化,但是也没见过他变过什么。所以我们可以写死KernelCallbackTable的偏移。说稍微有点麻烦就是指的,这个偏移在32bit和64bit的系统上是不同的而已,32位系统的偏移是0x2c,64位系统是0x58。另外一个就是获得PEB的方法了,32位程序你既可以写点汇编从fs中获取,也能调用__readfsdword获得,64位程序会麻烦点,你需要先获得TEB,然后从TEB里得到PEB,至于获得TEB的方法,你可以直接调用__readgsqword获得,也可以调用ntdll的NtCurrentTeb获得。
__ClientLoadLibrary在数组中的index
这个就稍微繁琐点,我们需要把我们关心的系统用windbg带上符号都看一眼才能知道是多少了。
我这里提供几个常用系统中__ClientLoadLibrary在数组中的index:
XP=0x42,Win7=0x41,Win8.1=0x47
好了,知道了这些,后面的就不用说太详细了,无非就是这三步:
OK,大功告成了。
这两天有个朋友一直问我用用户普通权限连接minifilter server port的问题。给他解答的同时,也发现了这个方面的一个问题。首先说用普通用户权限连接port的方法,其实就是设置FltCreateCommunicationPort参数里ObjectAttributes的SecurityDescriptor,加入everyone的ACE就行了。那么加入everyone的ace你就要指定一个ACCESS_MASK,在MSDN里,介绍了两个可以使用的MASK

其中FLT_PORT_CONNECT=1,FLT_PORT_ALL_ACCESS=1F0001。看到这里,多数人都可能会认为如果只想让everyone连接上去,不给他所用权限,那么在这个ACE里加入FLT_PORT_CONNECT就可以了。然后就掉到微软的坑里了,和我那个朋友一样:)。
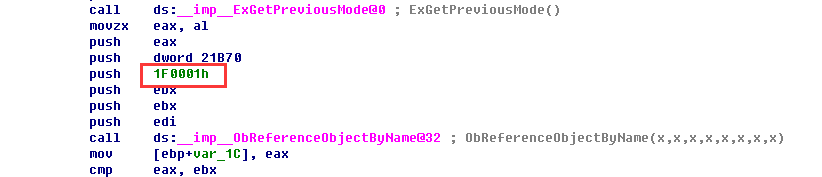
实际上指定FLT_PORT_CONNECT会让R3的程序无法连接驱动的port,原因就是FilterConnectCommunicationPort函数没有让你指定你需求的ACCESS,而是在底层打开port的时候直接请求FLT_PORT_ALL_ACCESS。这个时候如果你的ACE里面是FLT_PORT_CONNECT,那当然无法连接上去了。所以这里把ACE里的ACCESS_MASK设置为FLT_PORT_ALL_ACCESS就行了。
